Reading from an output database¶
The following sections describe how you use Abaqus Scripting Interface commands to read data from an output database.
The Abaqus/CAE Visualization module tutorial output database¶
The following sections describe how you can access the data in an output database. Examples are included that refer to the Abaqus/CAE Visualization module tutorial output database, viewer_tutorial.odb. This database is generated by the input file from Case 2 of the example problem, Indentation of an elastomeric foam specimen with a hemispherical punch. The problem studies the behavior of a soft elastomeric foam block indented by a heavy metal punch. The tutorial shows how you can use the Visualization module to view the data in the output database. The tutorial describes how you can choose the variable to display, how you can step through the steps and frames in the analysis, and how you can create X - Y data from history output.
You are encouraged to copy the tutorial output database to a local directory and experiment with the Abaqus Scripting Interface. The output database and the example scripts from this guide can be copied to the user’s working directory using the abaqus fetch utility:
abaqus fetch job=name
where name.py is the name of the script or name.odb is the name of the output database (see Fetching sample input files). For example, use the following command to retrieve the tutorial output database:
abaqus fetch job=viewer_tutorial
Making the Odb commands available¶
To make the Odb commands available to your script, you first need to import the odbAccess module using the following statements:
from odbAccess import *
from abaqusConstants import *
To make the material and section Odb commands available to your script, you also need to import the relevant module using the following statements:
from odbMaterial import *
from odbSection import *
Opening an output database¶
You use the openOdb method to open an existing output database. For example, the following statement opens the output database used by the Abaqus/CAE Visualization module tutorial:
odb = openOdb(path="viewer_tutorial.odb")
After you open the output database, you can access its contents using the methods and members of the Odb object returned by the openOdb method. In the above example the Odb object is referred to by the variable odb. For a full description of the openOdb command, see openOdb().
Reading model data¶
The following list describes the objects in model data and the commands you use to read model data. Many of the objects are repositories, and you will find the keys() method useful for determining the names of the objects in the repository. For more information, see Using dictionaries and Repositories.
The root assembly
An output database contains only one root assembly. You access the root assembly through the OdbAssembly object.
myAssembly = odb.rootAssemblyPart instances
Part instances are stored in the instances repository under the OdbAssembly object. The following statements display the repository keys of the part instances in the tutorial output database:
for instanceName in odb.rootAssembly.instances.keys(): print(instanceName)The output database contains only one part instance, and the resulting output is
PART - 1 - 1Regions
Regions in the output database are OdbSet objects. Regions refer to the part and assembly sets stored in the output database. A part set refers to elements or nodes in an individual part and appears in each instance of the part in the assembly. An assembly set refers to the elements or nodes in part instances in the assembly. A region can be one of the following:
A node set
An element set
A surface
For example, the following statement displays the node sets in the OdbAssembly object:
print("Node sets = ", odb.rootAssembly.nodeSets.keys())The resulting output is
Node sets = ['ALL NODES']The following statements display the node sets and the element sets in the PART-1-1 part instance:
The resulting output is
Node sets = ['ALLN', 'BOT', 'CENTER', 'N1', 'N19', 'N481', 'N499', 'PUNCH', 'TOP'] Element sets = ['CENT', 'ETOP', 'FOAM', 'PMASS', 'UPPER']The following statement assigns a variable (topNodeSet) to the ‘TOP’ node set in the PART-1-1 part instance:
topNodeSet = odb.rootAssembly.instances["PART-1-1"].nodeSets["TOP"]The type of the object to which topNodeSet refers is OdbSet. After you create a variable that refers to a region, you can use the variable to refer to a subset of field output data, as described in [using regions to read a subset of field output data].
Materials
You can read material data from an output database.
Materials are stored in the materials repository under the Odb object.
Access the materials repository using the command:
allMaterials = odb.materials for materialName in allMaterials.keys(): print("Material Name : ", materialName)To print isotropic elastic material properties in a material object:
for material in allMaterials.values(): if hasattr(material, "elastic"): elastic = material.elastic if elastic.type == ISOTROPIC: print("isotropic elastic behavior, type = %s" % elastic.moduli) title1 = "Young modulus Poisson's ratio " title2 = "" if elastic.temperatureDependency == ON: title2 = "Temperature " dep = elastic.dependencies title3 = "" for x in range(dep): title3 += " field # %d" % x print("%s %s %s" % (title1, title2, title3)) for dataline in elastic.table: print(dataline)Some Material definitions have suboptions. For example, to access the smoothing type used for biaxial test data specified for a hyperelastic material:
Material describes the Material object commands in more detail.
Sections
You can read section data from an output database.
Sections are stored in the sections repository under the Odb object.
The following statements display the repository keys of the sections in an output database:
allSections = odb.sections for sectionName in allSections.keys(): print("Section Name : ", sectionName)The Section object can be one of the various section types. The type command provides information on the section type. For example, to determine whether a section is of type homogeneous solid section and to print its thickness and associated material name:
Similarily, to access the beam profile repository:
The Profile object can be one of the various profile types. The type command provides information on the profile type. For example, to output the radius of all circular profiles in the odb:
Section assignments
Section assignments are stored in the odbSectionAssignmentArray repository under the OdbAssembly object.
All elements in an Abaqus analysis need to be associated with section and material properties. Section assignments provide the relationship between elements in a part instance and their section properties. The section properties include the associated material name. To access the sectionAssignments repository from the PartInstance object:
instances = odb.rootAssembly.instances for instance in instances.values(): assignments = instance.sectionAssignments print("Instance : ", instance.name) for sa in assignments: region = sa.region elements = region.elements print(" Section : ", sa.sectionName) print(" Elements associated with this section : ") for e in elements: print(" label : ", e.label)Analytical rigid surfaces
Analytical rigid surfaces are defined under a OdbPart object or a OdbInstance object. Each OdbPart or OdbInstance can have only one analytical rigid surface.
Rigid bodies
Rigid bodies are stored in the odbRigidBodyArray. The OdbPart object, OdbInstance object, and OdbAssembly object each have an odbRigidBodyArray.
Pretension sections
Pretension sections are stored in odbPretensionSectionArray under the OdbAssembly object.
Reading results data¶
The following list describes the objects in results data and the commands you use to read results data. As with model data you will find it useful to use the keys() method to determine the keys of the results data repositories.
Steps
Steps are stored in the steps repository under the Odb object. The key to the steps repository is the name of the step. The following statements print out the keys of each step in the repository:
for stepName in odb.steps.keys(): print(stepName)The resulting output is
Step - 1 Step - 2 Step - 3Note
An index of 0 in a sequence refers to the first value in the sequence, and an index of −1 refers to the last value. You can use the following syntax to refer to an individual item in a repository:
step1 = odb.steps.values()[0] print(step1.name)The resulting output is
Step-1Frames
Each step contains a sequence of frames, where each increment of the analysis (or each mode in an eigenvalue analysis) that resulted in output to the output database is called a frame. The following statement assigns a variable to the last frame in the first step:
lastFrame = odb.steps["Step-1"].frames[-1]
Reading field output data¶
Field output data are stored in the fieldOutputs repository under the OdbFrame object. The key to the repository is the name of the variable. The following statements list all the variables found in the last frame of the first step (the statements use the variable lastFrame that we defined previously):
>>> for fieldName in lastFrame.fieldOutputs.keys():
... print(fieldName)
...
COPEN TARGET/IMPACTOR
CPRESS TARGET/IMPACTOR
CSHEAR1 TARGET/IMPACTOR
CSLIP1 TARGET/IMPACTOR
LE
RF
RM3
S
U
UR3
Different variables can be written to the output database at different frequencies. As a result, not all frames will contain all the field output variables.
You can use the following to view all the available field data in a frame:
# For each field output value in the last frame,
# print the name, description, and type members.
for f in lastFrame.fieldOutputs.values():
print(f.name, ":", f.description)
print("Type: ", f.type)
# For each location value, print the position.
for loc in f.locations:
print("Position:", loc.position)
print()
The resulting print output lists all the field output variables in a particular frame, along with their type and position.
COPEN TARGET/IMPACTOR : Contact opening
Type: SCALAR
Position: NODAL
CPRESS TARGET/IMPACTOR : Contact pressure
Type: SCALAR
Position: NODAL
CSHEAR1 TARGET/IMPACTOR : Frictional shear
Type: SCALAR
Position: NODAL
CSLIP1 TARGET/IMPACTOR : Relative tangential motion direction 1
Type: SCALAR
Position: NODAL
LE : Logarithmic strain components
Type: TENSOR_2D_PLANAR
Position: INTEGRATION_POINT
RF : Reaction force
Type: VECTOR
Position: NODAL
RM3 : Reaction moment
Type: SCALAR
Position: NODAL
S : Stress components
Type: TENSOR_2D_PLANAR
Position: INTEGRATION_POINT
U : Spatial displacement
Type: VECTOR
Position: NODAL
UR3 : Rotational displacement
Type: SCALAR
Position: NODAL
In turn, a FieldOutput object has a member values that is a sequence of FieldValue objects that contain data. Each data value in the sequence has a particular location in the model. You can query the FieldValue object to determine the location of a data value; for example,
displacement = lastFrame.fieldOutputs["U"]
fieldValues = displacement.values
# For each displacement value, print the nodeLabel
# and data members.
for v in fieldValues:
print("Node = %d U[x] = %6.4f, U[y] = %6.4f" % (v.nodeLabel, v.data[0], v.data[1]))
The resulting output is
Node = 1 U[x] = 0.0000, U[y] = -76.4580
Node = 3 U[x] = -0.0000, U[y] = -64.6314
Node = 5 U[x] = 0.0000, U[y] = -52.0814
Node = 7 U[x] = -0.0000, U[y] = -39.6389
Node = 9 U[x] = -0.0000, U[y] = -28.7779
Node = 11 U[x] = -0.0000, U[y] = -20.3237...
The data in the FieldValue object depend on the field output variable, which is displacement in the above example. The following command lists all the members of a particular FieldValue object:
fieldValues[0].__members__
The resulting output is
['instance', 'elementLabel', 'nodeLabel', 'position',
'face', 'integrationPoint', 'sectionPoint',
'localCoordSystem', 'type', 'data', 'magnitude',
'mises', 'tresca', 'press', 'inv3', 'maxPrincipal',
'midPrincipal', 'minPrincipal', 'maxInPlanePrincipal',
'minInPlanePrincipal', 'outOfPlanePrincipal']
Where applicable, you can obtain section point information from the FieldValue object.
Using regions to read a subset of field output data¶
After you have created an OdbSet object using model data, you can use the getSubset method to read only the data corresponding to that region. Typically, you will be reading data from a region that refers to a node set or an element set. For example, the following statements create a variable called center that refers to the node set PUNCH at the center of the hemispherical punch. In a previous section you created the displacement variable that refers to the displacement of the entire model in the final frame of the first step. Now you use the getSubset command to get the displacement for only the center region.
center = odb.rootAssembly.instances["PART-1-1"].nodeSets["PUNCH"]
centerDisplacement = displacement.getSubset(region=center)
centerValues = centerDisplacement.values
for v in centerValues:
print(v.nodeLabel, v.data)
The resulting output is
1000 array([0.0000, -76.4555], 'd')
The arguments to getSubset are a region, an element type, a position, or section point data. The following is a second example that uses an element set to define the region and generates formatted output. For more information on tuples, the len() function, and the range() `function, see :doc:/user/python/introduction/python-basics:sequences` and Sequence operations.
opCenter = odb.rootAssembly.instances["PART-1-1"].elementSets["CENT"]
stressField = odb.steps["Step-2"].frames[3].fieldOutputs["S"]
# The following variable represents the stress at
# integration points for CAX4 elements from the
# element set "CENT."
field = stressField.getSubset(
region=topCenter, position=INTEGRATION_POINT, elementType="CAX4"
)
fieldValues = field.values
for v in fieldValues:
print(
"Element label = ",
v.elementLabel,
)
if v.integrationPoint:
print("Integration Point = ", v.integrationPoint)
else:
print()
# For each tensor component.
for component in v.data:
# Print using a format. The comma at the end of the
# print statement suppresses the carriage return.
print(
"%-10.5f" % component,
)
# After each tuple has printed, print a carriage return.
print()
The resulting output is
Element label = 1 Integration Point = 1
S : 0.01230 -0.05658 0.00892 -0.00015
Element label = 1 Integration Point = 2
S : 0.01313 -0.05659 0.00892 -0.00106
Element label = 1 Integration Point = 3
S : 0.00619 -0.05642 0.00892 -0.00023
Element label = 1 Integration Point = 4
S : 0.00697 -0.05642 0.00892 -0.00108
Element label = 11 Integration Point = 1
S : 0.01281 -0.05660 0.00897 -0.00146
Element label = 11 Integration Point = 2
S : 0.01183 -0.05651 0.00897 -0.00257
Element label = 11 Integration Point = 3 ...
Possible values for the position argument to the getSubset command are:
INTEGRATION_POINT
NODAL
ELEMENT_NODAL
CENTROID
If the requested field values are not found in the output database at the specified ELEMENT_NODAL or CENTROID positions, they are extrapolated from the field data at the INTEGRATION_POINT position.
Reading history output data¶
History output is output defined for a single point or for values calculated for a portion of the model as a whole, such as energy. Depending on the type of output expected, the historyRegions repository contains data from one of the following:
a node
an integration point
a region
a material point
Note
History data from an analysis cannot contain multiple points.
The history data object model is shown in Fig. 29
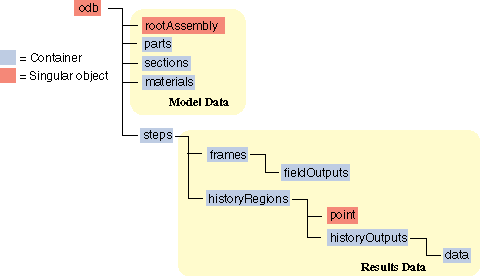
Fig. 29 The history data object model.¶
In contrast to field output, which is associated with a frame, history output is associated with a step. History output data are stored in the historyRegions repository under an OdbStep object. Abaqus creates keys to the historyRegions repository that describe the region; for example,
'Node PART-1-1.1000''Element PART-1-1.2 Int Point 1''Assembly ASSEMBLY'
The output from all history requests that relate to a specified point is collected in one HistoryRegion object. A HistoryRegion object contains multiple HistoryOutput objects. Each HistoryOutput object, in turn, contains a sequence of (frameValue, value) sequences. In a time domain analysis (domain = TIME) the sequence is a tuple of (stepTime, value). In a frequency domain analysis (domain = FREQUENCY) the sequence is a tuple of (frequency, value). In a modal domain analysis (domain = MODAL) the sequence is a tuple of (mode, value).
In the analysis that generated the Abaqus/CAE Visualization module tutorial output database, the user asked for the following history output:
At the rigid body reference point (Node 1000)
U
V
A
At the corner element
MISES
LE22
S22
The history output data can be retrieved from the HistoryRegion objects in the output database. The tutorial output database contains HistoryRegion objects that relate to the rigid body reference point and the integration points of the corner element as follows:
'Node PART-1-1.1000''Element PART-1-1.1 Int Point 1''Element PART-1-1.1 Int Point 2''Element PART-1-1.1 Int Point 3''Element PART-1-1.1 Int Point 4'
The following statements read the tutorial output database and write the U2 history data from the second step to an ASCII file that can be plotted by Abaqus/CAE:
from odbAccess import *
odb = openOdb(path="viewer_tutorial.odb")
step2 = odb.steps["Step-2"]
region = step2.historyRegions["Node PART-1-1.1000"]
u2Data = region.historyOutputs["U2"].data
dispFile = open("disp.dat", "w")
for time, u2Disp in u2Data:
dispFile.write("%10.4E %10.4E\n" % (time, u2Disp))
dispFile.close()
The output in this example is a sequence of tuples containing the frame time and the displacement value. The example uses nodal history data output. If the analysis requested history output from an element, the output database would contain one HistoryRegion object and one HistoryPoint object for each integration point.
An example of reading node and element information from an output database¶
The following script illustrates how you can open the output database used by the Abaqus/CAE Visualization module tutorial output database and print out some nodal and element information. Use the following commands to retrieve the example script and the tutorial output database:
abaqus fetch job=odbElementConnectivity
abaqus fetch job=viewer_tutorial
# odbElementConnectivity.py
# Script to extract node and element information.
#
# Command line argument is the path to the output
# database.
#
# For each node of each part instance:
# Print the node label and the nodal coordinates.
#
# For each element of each part instance:
# Print the element label, the element type, the
# number of nodes, and the element connectivity.
from odbAccess import *
import sys
# Check that an output database was specified.
if len(sys.argv) != 2:
print("Error: you must supply the name \
of an odb on the command line")
sys.exit(1)
# Get the command line argument.
odbPath = sys.argv[1]
# Open the output database.
odb = openOdb(path=odbPath)
assembly = odb.rootAssembly
# Model data output
print("Model data for ODB: ", odbPath)
# For each instance in the assembly.
numNodes = numElements = 0
for name, instance in assembly.instances.items():
n = len(instance.nodes)
print("Number of nodes of instance %s: %d" % (name, n))
numNodes = numNodes + n
print()
print("NODAL COORDINATES")
# For each node of each part instance
# print the node label and the nodal coordinates.
# Three-dimensional parts include X-, Y-, and Z-coordinates.
# Two-dimensional parts include X- and Y-coordinates.
if instance.embeddedSpace == THREE_D:
print(" X Y Z")
for node in instance.nodes:
print(node.coordinates)
else:
print(" X Y")
for node in instance.nodes:
print(node.coordinates)
# For each element of each part instance
# print the element label, the element type, the
# number of nodes, and the element connectivity.
n = len(instance.elements)
print("Number of elements of instance ", name, ": ", n)
numElements = numElements + n
print("ELEMENT CONNECTIVITY")
print(" Number Type Connectivity")
for element in instance.elements:
print(
"%5d %8s" % (element.label, element.type),
)
for nodeNum in element.connectivity:
print(
"%4d" % nodeNum,
)
print()
print()
print("Number of instances: ", len(assembly.instances))
print("Total number of elements: ", numElements)
print("Total number of nodes: ", numNodes)
An example of reading field data from an output database¶
The following script combines many of the commands you have already seen and illustrates how you read model data and field output data from the output database used by the Abaqus/CAE Visualization module tutorial. Use the following commands to retrieve the example script and the tutorial output database: .. code-block:: sh
abaqus fetch job=odbRead abaqus fetch job=viewer_tutorial
# odbRead.py
# A script to read the Abaqus/CAE Visualization module tutorial
# output database and read displacement data from the node at
# the center of the hemispherical punch.
from odbAccess import *
odb = openOdb(path="viewer_tutorial.odb")
# Create a variable that refers to the
# last frame of the first step.
lastFrame = odb.steps["Step-1"].frames[-1]
# Create a variable that refers to the displacement 'U'
# in the last frame of the first step.
displacement = lastFrame.fieldOutputs["U"]
# Create a variable that refers to the node set 'PUNCH'
# located at the center of the hemispherical punch.
# The set is associated with the part instance 'PART-1-1'.
center = odb.rootAssembly.instances["PART-1-1"].nodeSets["PUNCH"]
# Create a variable that refers to the displacement of the node
# set in the last frame of the first step.
centerDisplacement = displacement.getSubset(region=center)
# Finally, print some field output data from each node
# in the node set (a single node in this example).
for v in centerDisplacement.values:
print("Position = ", v.position, "Type = ", v.type)
print("Node label = ", v.nodeLabel)
print("X displacement = ", v.data[0])
print("Y displacement = ", v.data[1])
print("Displacement magnitude =", v.magnitude)
odb.close()
The resulting output is
Position = NODAL Type = VECTOR
Node label = 1000
X displacement = -8.29017850095e-34
Y displacement = -76.4554519653
Displacement magnitude = 76.4554519653